Lab Session #8
# Agenda
# Non-deterministic FSA NDFSA to (D)FSA Regular Expressions (RegExp) Non-deterministic Finite State Automata (NDFSA)
# Definition
# A NDFSA is a tuple
⟨ Q , I , δ , q 0 , F ⟩ \lang Q, I, \delta, q_0, F\rang ⟨ Q , I , δ , q 0 , F ⟩
, where Q , I , q 0 , F Q, I, q_0, F Q , I , q 0 , F
δ : Q × I → P ( Q ) \delta : Q \times I \to \mathbb{P}(Q) δ : Q × I → P ( Q ) P \mathbb{P} P
A NDFSA modifies the definition of a FSA to permit transitions at
each stage to either zero, one, or more than one states.
The extended transition δ* for NDFSA
# Let M = ⟨ Q , I , δ , q 0 , F ⟩ M = \lang Q, I, \delta, q_0, F\rang M = ⟨ Q , I , δ , q 0 , F ⟩
For every q ∈ Q q \in Q q ∈ Q δ ∗ ( q , ϵ ) = { q } \delta^\ast(q,\epsilon) = \{q\} δ ∗ ( q , ϵ ) = { q } For every q ∈ Q q \in Q q ∈ Q y ∈ I ∗ y \in I^\ast y ∈ I ∗ i ∈ I i \in I i ∈ I δ ∗ ( q , y i ) = ⋃ q ′ ∈ δ ∗ ( q , y ) δ ( q ′ , i ) \delta^\ast(q,yi) = \bigcup_{q'\in\delta^\ast(q,y)}\delta(q',i) δ ∗ ( q , y i ) = q ′ ∈ δ ∗ ( q , y ) ⋃ δ ( q ′ , i ) Acceptance by a NDFSA
# Let M = ⟨ Q , I , δ , q 0 , F ⟩ M = \lang Q, I, \delta, q_0, F\rang M = ⟨ Q , I , δ , q 0 , F ⟩ x ∈ I ∗ x \in I^\ast x ∈ I ∗ x x x M M M
δ ∗ ( q 0 , x ) ∩ F ≠ ∅ \delta^\ast(q_0,x)\cap F \neq \varnothing δ ∗ ( q 0 , x ) ∩ F = ∅ and it is rejected by M M M
Notion: Among the various possible runs (with the same input) of the NDFSA, it is sufficient that one of them succeeds to accept the input string.
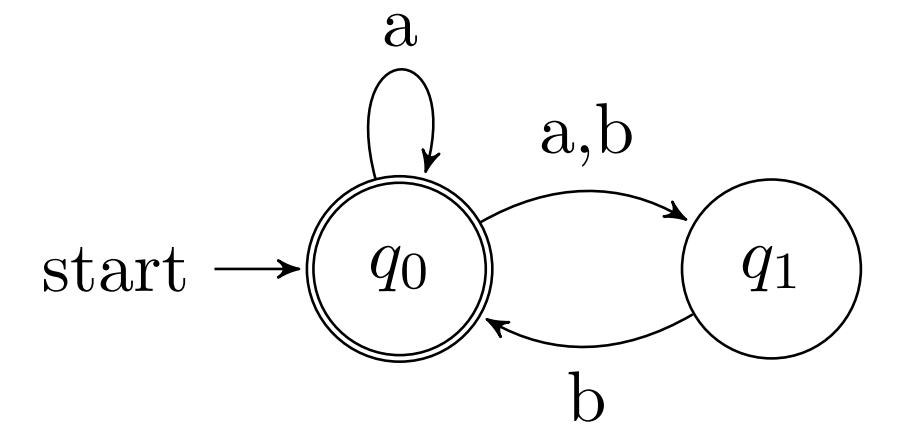
Exercises on NDFSA
# Build NDFSAs that recognise the following languages:
L a = { x ∈ { 0 , 1 } ∗ ∣ x L_a = \{x \in \{0, 1\}^* \mid x L a = { x ∈ { 0 , 1 } ∗ ∣ x 101 } 101\} 1 0 1 } L b = { x y ∣ x ∈ { a } ∗ ∧ y ∈ { a , b } ∗ ∧ y L_b = \{xy \mid x \in \{a\}^* \wedge y \in \{a, b\}^* \wedge y L b = { x y ∣ x ∈ { a } ∗ ∧ y ∈ { a , b } ∗ ∧ y ‘ b ’ ∧ \text{\textquoteleft}b\text{\textquoteright} \wedge ‘ b ’ ∧ ‘ a ’ \text{\textquoteleft} a \text{\textquoteright} ‘ a ’ y y y ‘ b ’ } \text{\textquoteleft}b\text{\textquoteright}\} ‘ b ’ } L a = { x ∈ { a , b , c } ∗ ∣ x L_a = \{x \in \{a, b, c\}^* \mid x L a = { x ∈ { a , b , c } ∗ ∣ x a b ab a b b c bc b c c a } ca\} c a } Solutions
▾
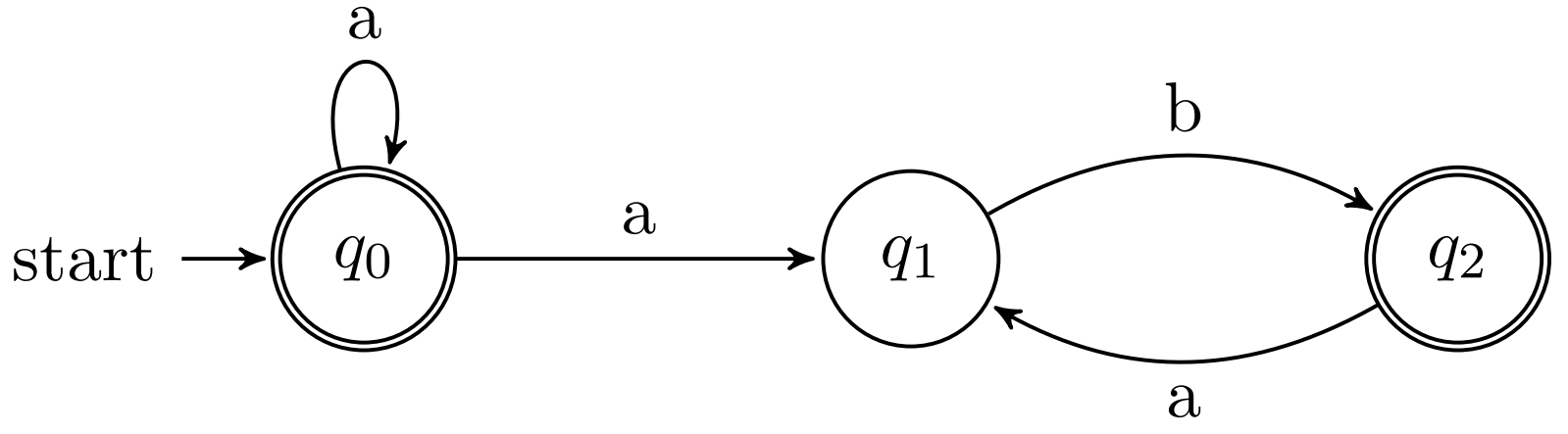
NDFSA that recognises the language:
L a = { x ∈ { 0 , 1 } ∗ ∣ x L_a = \{x \in \{0, 1\}^* \mid x L a = { x ∈ { 0 , 1 } ∗ ∣ x
ends with
101 } 101\} 1 0 1 }
;
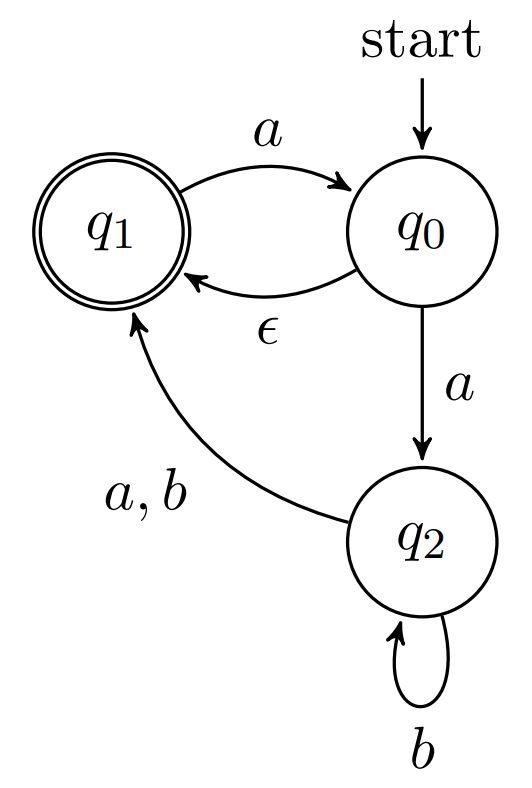
NDFSA that recognises the language:
L b = { x y ∣ x ∈ { a } ∗ ∧ y ∈ { a , b } ∗ ∧ y L_b = \{xy \mid x \in \{a\}^* \wedge y \in \{a, b\}^* \wedge y L b = { x y ∣ x ∈ { a } ∗ ∧ y ∈ { a , b } ∗ ∧ y
does not start with
‘ b ’ ∧ \text{\textquoteleft}b\text{\textquoteright} \wedge ‘ b ’ ∧
every
‘ a ’ \text{\textquoteleft} a \text{\textquoteright} ‘ a ’
in
y y y
is followed by exactly one
‘ b ’ } \text{\textquoteleft}b\text{\textquoteright}\} ‘ b ’ }
;
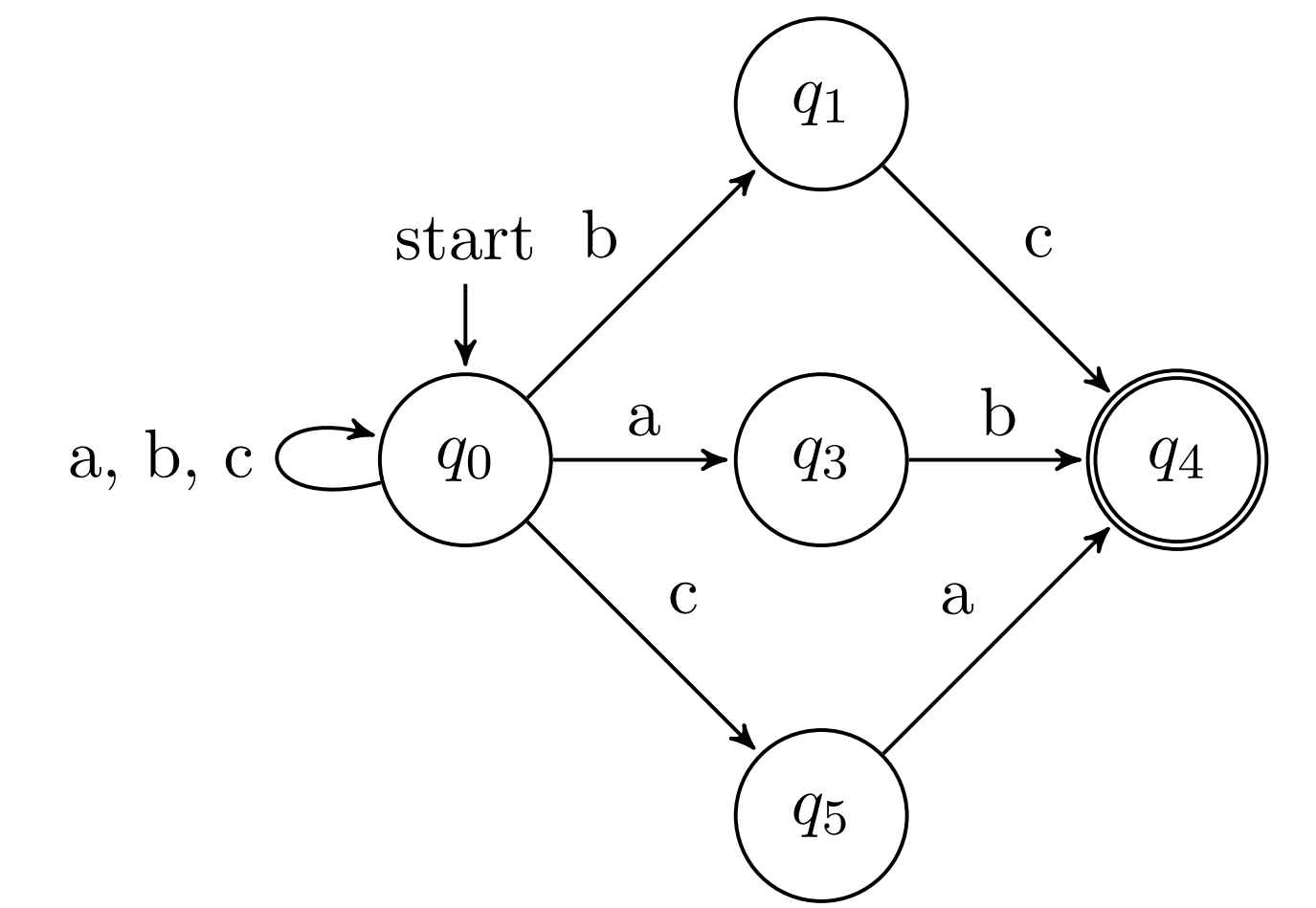
NDFSA that recognises the language:
L a = { x ∈ { a , b , c } ∗ ∣ x L_a = \{x \in \{a, b, c\}^* \mid x L a = { x ∈ { a , b , c } ∗ ∣ x
ends with either
a b ab a b
,
b c bc b c
or
c a } ca\} c a }
;
NDFSA to DFSA
# Algorithm for NDFSA to DFSA
# Create state table from the given NDFA Create a blank state table under possible input alphabets for the equivalent DFA Mark the start state of the DFA by q 0 q_0 q 0 Find out the combination of States q 0 , q 1 , . . . , q n q_0, q_1, ..., q_n q 0 , q 1 , . . . , q n Each time we generate a new DFA state under the input alphabet columns, we have to apply step 4 4 4 6 6 6 The states which contain any of the accepting states of the
NDFA are the accepting states of the equivalent DFA Simple example (1)
#
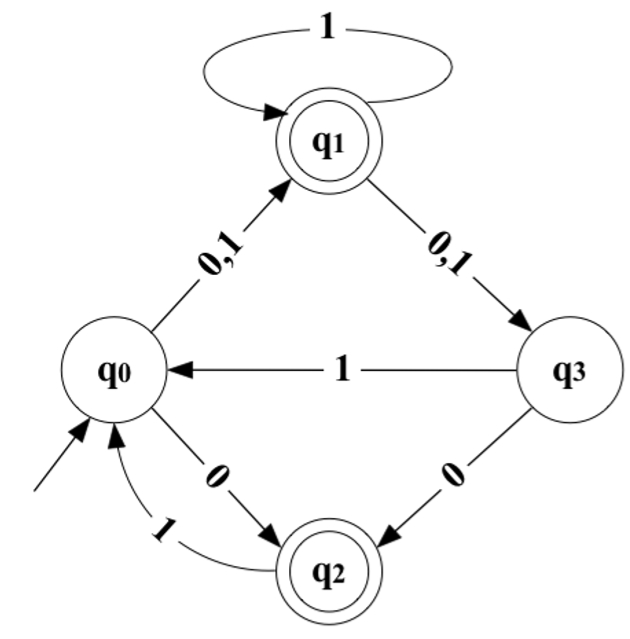
Example with steps
# Let us consider the following NDFSA:
First, we build a transition table for NDFSA:
Using table from previous step, let us create a similar table, but this time for FSA. Initially, the table is empty:
We begin by adding the initial state and the set of states:
The initial state can take us to two new states that are not yet in the table. Note that we treat a set of states as a single state now!
The next step is to find possible states for { q 1 , q 2 } \{q_1,q_2\} { q 1 , q 2 } q 3 q_3 q 3 q 3 q_3 q 3 { q 1 , q 2 } \{q_1,q_2\} { q 1 , q 2 } δ ( q 1 , q 2 , 0 ) = δ ( q 1 , 0 ) ∪ δ ( q 2 , 0 ) = { q 3 } \delta({q_1,q_2},0) = \delta(q_1,0) \cup \delta(q_2,0) = \{q_3\} δ ( q 1 , q 2 , 0 ) = δ ( q 1 , 0 ) ∪ δ ( q 2 , 0 ) = { q 3 } δ ( q 1 , q 2 , 1 ) = δ ( q 1 , 1 ) ∪ δ ( q 2 , 1 ) = { q 0 , q 1 , q 3 } \delta({q_1,q_2},1) = \delta(q_1,1) \cup \delta(q_2,1) = \{q_0,q_1,q_3\} δ ( q 1 , q 2 , 1 ) = δ ( q 1 , 1 ) ∪ δ ( q 2 , 1 ) = { q 0 , q 1 , q 3 }
Repeat the steps above until we have included all states from the original NDFSA and there are no new states.
Step 5
▾
…
After repeating previous steps and depicting final states we will arrive to the following table:
The result will be the following:
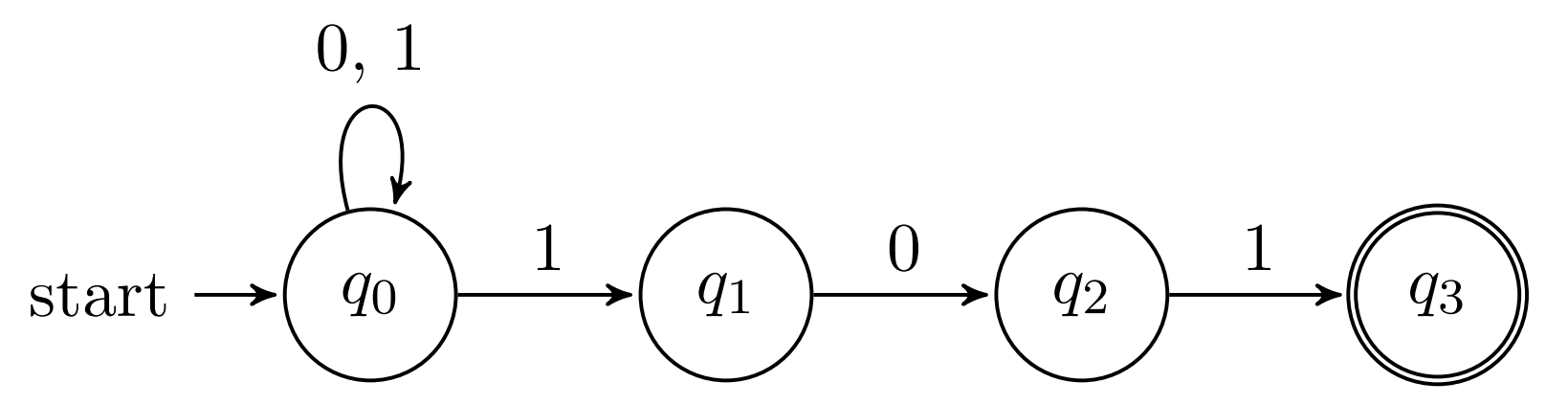
Exercise 1
# Build DFSA from the NDFSA that recognizes the language:
L 1 = { x ∈ { 0 , 1 } ∗ ∣ x L_1 = \{x \in \{0, 1\}^* \mid x L 1 = { x ∈ { 0 , 1 } ∗ ∣ x 101 } 101\} 1 0 1 }
Exercise 2
# Build DFSA from the NDFSA that recognizes the language:
L 2 = { x y ∣ x ∈ { a } ∗ ∧ y ∈ { a , b } ∗ ∧ y L_2 = \{xy \mid x \in \{a\}^* \wedge y \in \{a, b\}^* \wedge y L 2 = { x y ∣ x ∈ { a } ∗ ∧ y ∈ { a , b } ∗ ∧ y ‘ b ’ ∧ \text{\textquoteleft}b\text{\textquoteright} \wedge ‘ b ’ ∧ ‘ a ’ \text{\textquoteleft} a \text{\textquoteright} ‘ a ’ y y y ‘ b ’ } \text{\textquoteleft}b\text{\textquoteright}\} ‘ b ’ }
Exercise 3
# Build DFSA from the NDFSA that recognizes the language:
L 3 = { x ∈ { a , b , c } ∗ ∣ x L_3 = \{x \in \{a, b, c\}^* \mid x L 3 = { x ∈ { a , b , c } ∗ ∣ x a b ab a b b c bc b c c a } ca\} c a }
Regular Expressions (RegExp)
# Definition
# Inductive definition of RegExps over an alphabet Σ \Sigma Σ Basis.
Symbol ∅ \emptyset ∅ ∅ \emptyset ∅ Symbol ϵ \epsilon ϵ { ϵ } \{\epsilon\} { ϵ } Each symbol σ \sigma σ Σ \Sigma Σ L ( σ ) = { σ } L(\sigma) = \{\sigma\} L ( σ ) = { σ } σ ∈ Σ \sigma\in\Sigma σ ∈ Σ
Induction.
Let r r r s s s
( r ⋅ s ) (r\cdot{s}) ( r ⋅ s ) L ( ( r ⋅ s ) ) = { w w ′ ∣ ( w ∈ L ( r ) ∧ w ′ ∈ L ( s ) ) } L((r\cdot{s})) = \{ww'\mid(w \in L(r) \wedge w' \in L(s))\} L ( ( r ⋅ s ) ) = { w w ′ ∣ ( w ∈ L ( r ) ∧ w ′ ∈ L ( s ) ) } ( r ∣ s ) (r|s) ( r ∣ s ) L ( ( r ∣ s ) ) = L ( r ) ∪ L ( s ) L((r|s)) = L(r) \cup L(s) L ( ( r ∣ s ) ) = L ( r ) ∪ L ( s ) r ∗ r^* r ∗ L ( r ∗ ) = L ( r ) ∗ L(r^*) = L(r)^* L ( r ∗ ) = L ( r ) ∗ If A A A B B B
A ⋅ B = { x y | x ∈ A A\cdot{B} = \{xy\text{\textbar}x \in A A ⋅ B = { x y | x ∈ A y ∈ B } y \in B\} y ∈ B } A | B = { x | x ∈ A A\text{\textbar}B = \{x\text{\textbar}x \in A A | B = { x | x ∈ A x ∈ B } x \in B\} x ∈ B } A ∗ = { x 1 ⋅ x 2 ⋅ x 3 ⋅ . . . ⋅ x k | k ≥ 0 A^* = \{x_1\cdot{x_2}\cdot{x_3}\cdot{...}\cdot{x_k}\text{\textbar}k\geq 0 A ∗ = { x 1 ⋅ x 2 ⋅ x 3 ⋅ . . . ⋅ x k | k ≥ 0 x i ∈ A } x_i \in A\} x i ∈ A } are also RegExp.
It is also possible to use the following notation:
A + = { x 1 ⋅ x 2 ⋅ x 3 ⋅ . . . ⋅ x k | k ≥ 1 A^+ = \{x_1\cdot{x_2}\cdot{x_3}\cdot{...}\cdot{x_k}\text{\textbar}k\geq 1 A + = { x 1 ⋅ x 2 ⋅ x 3 ⋅ . . . ⋅ x k | k ≥ 1 x i ∈ A } x_i \in A\} x i ∈ A }
Exercises (1)
# Consider the alphabet Σ = { 0 , 1 } \Sigma = \{0, 1\} Σ = { 0 , 1 }
∅ \emptyset ∅ ∅ ∗ \emptyset{^*} ∅ ∗ ( 0 ∗ 1 ∗ ) ∗ 000 ( 0 | 1 ) ∗ (0 ^ \ast 1 ^ \ast )^\ast 000 ( 0 \text{\textbar} 1 )^\ast ( 0 ∗ 1 ∗ ) ∗ 0 0 0 ( 0 | 1 ) ∗ ( 1 | ϵ ) ( 0 0 ∗ 1 ) ∗ 0 ∗ (1\text{\textbar}\epsilon)(00^\ast 1)^\ast 0^\ast ( 1 | ϵ ) ( 0 0 ∗ 1 ) ∗ 0 ∗ Exercises (2)
# Consider the alphabet Σ = { a , b } \Sigma = \{a, b\} Σ = { a , b } a a a b b b a a a b b b a a aa a a a a a b b b
Homework on NDFSA
# A. Construct NDFSAs over alphabets Σ 1 = { a , b } \Sigma_1 = \{a, b\} Σ 1 = { a , b } Σ 2 = { 0 , 1 } \Sigma_2 = \{0, 1\} Σ 2 = { 0 , 1 }
L 0 = { x ∈ Σ 2 ∗ ∣ L_0 = \{x \in \Sigma_2^\ast \mid L 0 = { x ∈ Σ 2 ∗ ∣ 0 0 0 x x x 1 } 1\} 1 } Strings examplle: 010111 010111 0 1 0 1 1 1 1111 1111 1 1 1 1 01110111011 01110111011 0 1 1 1 0 1 1 1 0 1 1
L 1 = { x ∈ Σ 1 ∗ ∣ x L_1 = \{x \in \Sigma_1^\ast \mid x L 1 = { x ∈ Σ 1 ∗ ∣ x a b b a a b } abbaab\} a b b a a b }
L 2 = { x ∈ Σ 1 ∗ ∣ ∣ x ∣ ≥ 2 ∧ L_2 = \{x \in \Sigma_1^\ast \mid |x| \geq 2 \wedge L 2 = { x ∈ Σ 1 ∗ ∣ ∣ x ∣ ≥ 2 ∧ } \} }
L 3 = { x ∈ Σ 2 ∗ ∣ x L_3 = \{x \in \Sigma_2^\ast \mid x L 3 = { x ∈ Σ 2 ∗ ∣ x 5 5 5 } \} }
B. Convert NDFSAs from part A to DFSAs applying the algorithm presented in the lab.