Lab Session #10
# Agenda
# RegExp to (N)FSA: Thompson’s Construction FSA to RegExp: Kleene’s Algorithm From Regular Expression to (N)FSA.
# The Thompson’s Construction
# The Algorithm
# The algorithm works recursively by splitting an expression into its
constituent subexpressions, from which the (N)FSA will be
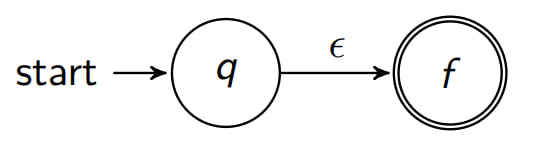
constructed using a set of rules (see below). Rule: the Empty Expression
# The empty-expression
ϵ ϵ ϵ
is converted to:
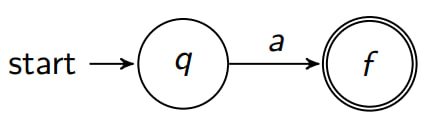
Rule: a symbo
# A symbol a of the input alphabet is converted to
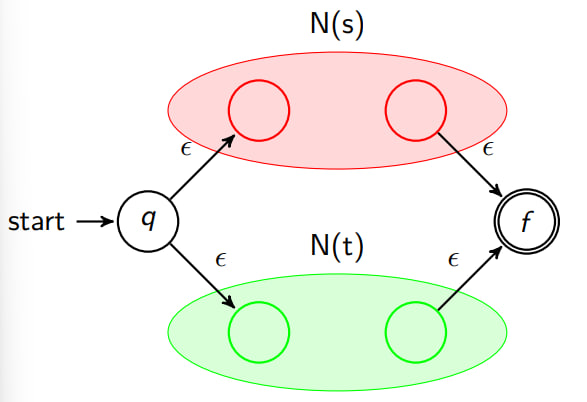
Rule: Concatenation Expression
# The concatenation expression st is converted to
N(s) and N(t) are the (N)FSA of the subexpression s and t,
respectively.
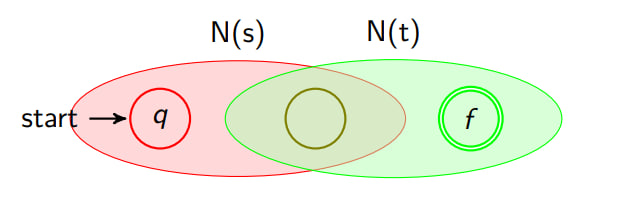
Rule: Union Expression
# The union expression s|t is converted to
N(s) and N(t) are the (N)FSA of the subexpression s and t,
respectively.
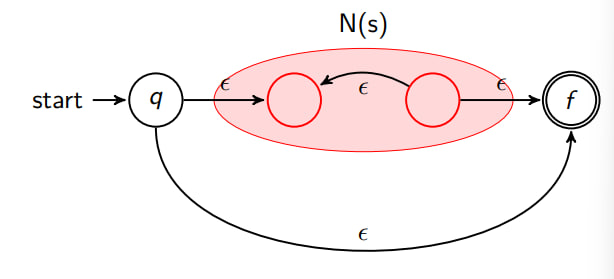
Rule: Kleene Star Expression
# The Kleene star expression s ∗ s
^∗ s ∗
N(s) is the (N)FSA of the subexpression s.
Example 1
# Build a (N)FSA for ( 1 ∣ 01 ) ∗ (1 | 01)^* ( 1 ∣ 0 1 ) ∗
Solution :
Exercises
# Build a (N)FSA for:
0 1 ∗ 01^* 0 1 ∗ ( 0 ∣ 1 ) 01 (0 | 1)01 ( 0 ∣ 1 ) 0 1 00 ( 0 ∣ 1 ) ∗ 00(0 | 1)^* 0 0 ( 0 ∣ 1 ) ∗ Solution.
# Expand
▾
1)- (N)FSA for (01^*)
2)- (N)FSA for ((0 | 1)01)
3_- (N)FSA for (00(0 | 1)^*)
FSA to RegExp
# Kleene’s Algorithm: from FSA to Regular Expression
# It transforms a given finite state automaton (FSA) into a regular
expression.
Description: Given an FSA M = ( Q , A , δ , q 0 , F ) M = (Q, A, δ, q_0, F) M = ( Q , A , δ , q 0 , F )
Q = q 0 , . . . , q n Q = {q0, . . . , qn} Q = q 0 , . . . , q n
the sets R i j k R^k_{ij} R i j k
q i j q_{ij} q i j
to
q j q_j q j
without going through any state numbered higher than k.
each set R i j k R^k_{ij} R i j k
the algorithm computes them step by step for k = − 1 , 0 , . . . , n . k = −1, 0, . . . , n. k = − 1 , 0 , . . . , n .
since there is no state numbered higher than n, the regular
expression
R 0 j n R^n_{0j} R 0 j n
represents the set of all strings that take M
from its start state q i q_i q i
q j q_j q j
.
If F = q i , . . . , q f F = {q_i
, . . . , q_f } F = q i , . . . , q f R 0 i n ∣ . . . ∣ R 0 f n R^
n
_{0i}
| . . . | R^
n
_{0f} R 0 i n ∣ . . . ∣ R 0 f n
Kleene’s Algorithm
# The initial regular expressions, for k = −1, are computed as
R i j − 1 = a 1 ∣ . . . ∣ a m R^
{−1}
_{ij} = a_1 | . . . | a_m R i j − 1 = a 1 ∣ . . . ∣ a m i = j i = j i = j
δ ( q i , a 1 ) = . . . = δ ( q i , a m ) = q j δ (q_i
, a_1) = . . . = δ (q_i
, a_m) = q_j δ ( q i , a 1 ) = . . . = δ ( q i , a m ) = q j
R i j − 1 = a 1 ∣ . . . ∣ a m ∣ ϵ R^
{−1}
_{ij} = a_1 | . . . | a_m|ϵ R i j − 1 = a 1 ∣ . . . ∣ a m ∣ ϵ i = j i = j i = j
δ ( q i , a 1 ) = . . . = δ ( q i , a m ) = q j δ (q_i
, a_1) = . . . = δ (q_i
, a_m) = q_j δ ( q i , a 1 ) = . . . = δ ( q i , a m ) = q j
After that, in each step the expressions R i k l R^k_il R i k l
R i j k R^k_{ij} R i j k R i k k − 1 R^{k-1}_{ik} R i k k − 1 ( R k k k − 1 ) ∗ (R^{k-1}_{kk})^* ( R k k k − 1 ) ∗ R k j k − 1 R^{k-1}_{kj} R k j k − 1 R i j k − 1 R^{k-1}_{ij} R i j k − 1
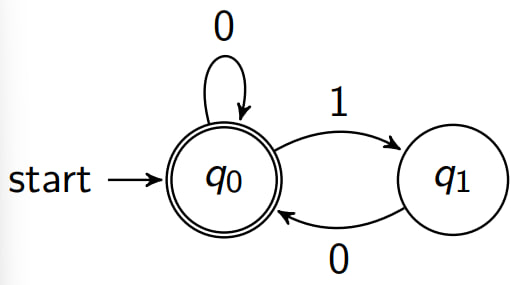
Kleene’s Algorithm: Example
# Give a regular expression that describes the language accepted by:
Initial Regular Expression (Step -1)
R 00 − 1 R^{-1}_{00} R 0 0 − 1 ϵ ϵ ϵ
R 01 − 1 R^{-1}_{01} R 0 1 − 1
R 10 − 1 R^{-1}_{10} R 1 0 − 1
R 11 − 1 R^{-1}_{11} R 1 1 − 1 ϵ ϵ ϵ
Step 0
R 00 0 R^{0}_{00} R 0 0 0 ( 0 ∣ ϵ ) (0 |ϵ) ( 0 ∣ ϵ ) ( 0 ∣ ϵ ) ∗ (0 |ϵ)^* ( 0 ∣ ϵ ) ∗ ( 0 ∣ ϵ ) (0 |ϵ) ( 0 ∣ ϵ ) ( 0 ∣ ϵ ) (0 |ϵ) ( 0 ∣ ϵ ) 0 ∗ 0^* 0 ∗
R 01 0 R^{0}_{01} R 0 1 0 ( 0 ∣ ϵ ) (0 |ϵ) ( 0 ∣ ϵ ) ( 0 ∣ ϵ ) ∗ (0 |ϵ)^* ( 0 ∣ ϵ ) ∗ 0 ∗ 1 0^*1 0 ∗ 1
R 10 0 R^{0}_{10} R 1 0 0 ( 0 ∣ ϵ ) ∗ (0 |ϵ)^* ( 0 ∣ ϵ ) ∗ ( 0 ∣ ϵ ) (0 |ϵ) ( 0 ∣ ϵ ) 0 0 ∗ 00^* 0 0 ∗
R 11 0 R^{0}_{11} R 1 1 0
( 0 ∣ ϵ ) ∗ (0 |ϵ)^* ( 0 ∣ ϵ ) ∗
1 |
ϵ ϵ ϵ 0 0 ∗ 1 00^*1 0 0 ∗ 1 ϵ ϵ ϵ
step 1
R 00 1 R^1_{00} R 0 0 1 ( 0 ∗ 1 ) (0^*1) ( 0 ∗ 1 ) ( 0 0 ∗ 1 ∣ ϵ ) ∗ (00^*1| ϵ)^* ( 0 0 ∗ 1 ∣ ϵ ) ∗ ( 0 0 ∗ ) ∣ 0 ∗ (00^*)|0^* ( 0 0 ∗ ) ∣ 0 ∗ ( 0 ∗ 1 ) (0^*1) ( 0 ∗ 1 ) ( 0 0 ∗ 1 ) ∗ (00^*1)^* ( 0 0 ∗ 1 ) ∗ ( 0 0 ∗ ) ∣ 0 ∗ (00^*)|0^* ( 0 0 ∗ ) ∣ 0 ∗
Do we need to compute the rest?
(i.e R 01 1 , R 10 1 , R 11 1 R^{1}_{01},R^{1}_{10},R^{1}_{11} R 0 1 1 , R 1 0 1 , R 1 1 1
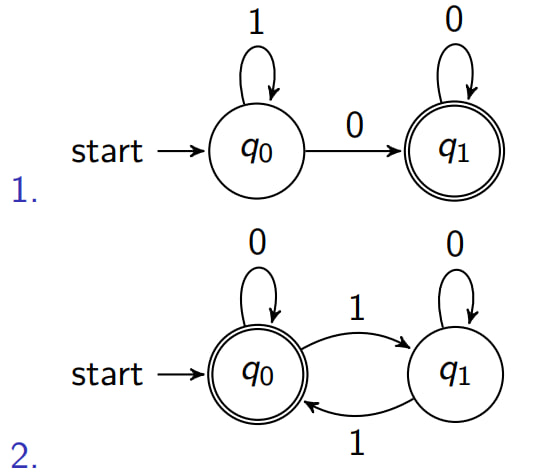
Exercises
# Give a regular expression that describes the language accepted by:
solution
# Expand
▾
(Step -1)
R 00 − 1 R^{-1}_{00} R 0 0 − 1
=
0 ∣ ϵ 0|ϵ 0 ∣ ϵ R 01 − 1 R^{-1}_{01} R 0 1 − 1
= 0
R 10 − 1 R^{-1}_{10} R 1 0 − 1
=
∅ ∅ ∅ R 11 − 1 R^{-1}_{11} R 1 1 − 1
=
0 ∣ ϵ 0|ϵ 0 ∣ ϵ (step 0)
R 00 0 R^{0}_{00} R 0 0 0
=
R 00 − 1 R^{-1}_{00} R 0 0 − 1 ( R 00 − 1 ) ∗ (R^{-1}_{00})^* ( R 0 0 − 1 ) ∗ R 00 − 1 R^{-1}_{00} R 0 0 − 1 ∣ R 00 − 1 |R^{-1}_{00} ∣ R 0 0 − 1
=
( 1 ∣ ϵ ) (1 |ϵ) ( 1 ∣ ϵ ) ( 1 ∣ ϵ ) ∗ (1 |ϵ)^* ( 1 ∣ ϵ ) ∗ ( 1 ∣ ϵ ) (1 |ϵ) ( 1 ∣ ϵ )
|
( 1 ∣ ϵ ) (1 |ϵ) ( 1 ∣ ϵ )
=
1 ∗ 1^* 1 ∗ R 01 0 R^{0}_{01} R 0 1 0
=
R 00 − 1 R^{-1}_{00} R 0 0 − 1 ( R 00 − 1 ) ∗ (R^{-1}_{00})^* ( R 0 0 − 1 ) ∗ R 01 − 1 R^{-1}_{01} R 0 1 − 1 ∣ R 01 − 1 |R^{-1}_{01} ∣ R 0 1 − 1
=
( 1 ∣ ϵ ) (1 |ϵ) ( 1 ∣ ϵ ) ( 1 ∣ ϵ ) ∗ (1 |ϵ)^* ( 1 ∣ ϵ ) ∗ 0 ∣ 0 0|0 0 ∣ 0
=
1 ∗ 0 1^*0 1 ∗ 0 R 10 0 R^{0}_{10} R 1 0 0
=
R 10 − 1 R^{-1}_{10} R 1 0 − 1 ( R 00 − 1 ) ∗ (R^{-1}_{00})^* ( R 0 0 − 1 ) ∗ R 00 − 1 R^{-1}_{00} R 0 0 − 1 ∣ R 10 − 1 |R^{-1}_{10} ∣ R 1 0 − 1
=
∅ ( 1 ∣ ϵ ) ∗ ∅(1 |ϵ)^* ∅ ( 1 ∣ ϵ ) ∗ ( 1 ∣ ϵ ) (1 |ϵ) ( 1 ∣ ϵ ) ∣ ∅ |∅ ∣ ∅
=
∅ ∅ ∅ R 11 0 R^{0}_{11} R 1 1 0
=
R 10 − 1 R^{-1}_{10} R 1 0 − 1 ( R 00 − 1 ) ∗ (R^{-1}_{00})^* ( R 0 0 − 1 ) ∗ R 01 − 1 R^{-1}_{01} R 0 1 − 1 ∣ R 11 − 1 |R^{-1}_{11} ∣ R 1 1 − 1
=
∅ ( 1 ∣ ϵ ) ∗ 0 ∅(1 |ϵ)^*0 ∅ ( 1 ∣ ϵ ) ∗ 0 ∣ ( 0 ∣ ϵ ) |(0 |ϵ) ∣ ( 0 ∣ ϵ )
=
( 0 ∣ ϵ ) (0 |ϵ) ( 0 ∣ ϵ ) step(1)
R 01 1 R^{1}_{01} R 0 1 1
=
R 01 0 R^{0}_{01} R 0 1 0 ( R 11 0 ) ∗ (R^{0}_{11})^* ( R 1 1 0 ) ∗ R 11 0 R^{0}_{11} R 1 1 0 ∣ R 01 0 |R^{0}_{01} ∣ R 0 1 0 = ( 1 ∗ 0 ) ( 0 ∣ ϵ ) ∗ ( 0 ∣ ϵ ) ∣ 1 ∗ 0 = 1 ∗ 0 0 ∗ ∣ 1 ∗ 0 = 1 ∗ 0 0 ∗ = (1^
∗0)(0|ϵ)^
∗
(0 |ϵ) | 1^
∗0
= 1^
∗00^∗
| 1^
∗0 = 1^
∗00^∗ = ( 1 ∗ 0 ) ( 0 ∣ ϵ ) ∗ ( 0 ∣ ϵ ) ∣ 1 ∗ 0 = 1 ∗ 0 0 ∗ ∣ 1 ∗ 0 = 1 ∗ 0 0 ∗ Do we need to compute the rest? (i.e
R 01 1 , R 10 1 , R 11 1 R^{1}_{01},R^{1}_{10},R^{1}_{11} R 0 1 1 , R 1 0 1 , R 1 1 1
)
Exercise 2 Solution
# (Step -1)
R 00 − 1 R^{-1}_{00} R 0 0 − 1
=0|
ϵ ϵ ϵ R 01 − 1 R^{-1}_{01} R 0 1 − 1
= 1
R 10 − 1 R^{-1}_{10} R 1 0 − 1
= 1
R 11 − 1 R^{-1}_{11} R 1 1 − 1
=
0 ∣ ϵ 0|ϵ 0 ∣ ϵ (step 0)
R 00 0 R^{0}_{00} R 0 0 0
=
R 00 − 1 R^{-1}_{00} R 0 0 − 1 ( R 00 − 1 ) ∗ (R^{-1}_{00})^* ( R 0 0 − 1 ) ∗ R 00 − 1 R^{-1}_{00} R 0 0 − 1 ∣ R 00 − 1 |R^{-1}_{00} ∣ R 0 0 − 1
=
( 0 ∣ ϵ ) (0 |ϵ) ( 0 ∣ ϵ ) ( 0 ∣ ϵ ) ∗ (0 |ϵ)^* ( 0 ∣ ϵ ) ∗ ( 0 ∣ ϵ ) (0 |ϵ) ( 0 ∣ ϵ )
|
( 0 ∣ ϵ ) (0 |ϵ) ( 0 ∣ ϵ )
=
0 ∗ 0^* 0 ∗ R 01 0 R^{0}_{01} R 0 1 0
=
R 00 − 1 R^{-1}_{00} R 0 0 − 1 ( R 00 − 1 ) ∗ (R^{-1}_{00})^* ( R 0 0 − 1 ) ∗ R 01 − 1 R^{-1}_{01} R 0 1 − 1 ∣ R 01 − 1 |R^{-1}_{01} ∣ R 0 1 − 1
=
( 0 ∣ ϵ ) (0 |ϵ) ( 0 ∣ ϵ ) ( 0 ∣ ϵ ) ∗ (0 |ϵ)^* ( 0 ∣ ϵ ) ∗ 1 ∣ 1 1|1 1 ∣ 1
=
0 ∗ 1 0^*1 0 ∗ 1 R 10 0 R^{0}_{10} R 1 0 0
=
R 10 − 1 R^{-1}_{10} R 1 0 − 1 ( R 00 − 1 ) ∗ (R^{-1}_{00})^* ( R 0 0 − 1 ) ∗ R 00 − 1 R^{-1}_{00} R 0 0 − 1 ∣ R 10 − 1 |R^{-1}_{10} ∣ R 1 0 − 1
=
1 ( 0 ∣ ϵ ) ∗ 1(0 |ϵ)^* 1 ( 0 ∣ ϵ ) ∗ ( 0 ∣ ϵ ) (0 |ϵ) ( 0 ∣ ϵ ) ∣ 1 |1 ∣ 1
=
1 0 ∗ 10^* 1 0 ∗ R 11 0 R^{0}_{11} R 1 1 0
=
R 10 − 1 R^{-1}_{10} R 1 0 − 1 ( R 00 − 1 ) ∗ (R^{-1}_{00})^* ( R 0 0 − 1 ) ∗ R 01 − 1 R^{-1}_{01} R 0 1 − 1 ∣ R 11 − 1 |R^{-1}_{11} ∣ R 1 1 − 1
=
1 ( 0 ∣ ϵ ) ∗ 1 1(0 |ϵ)^*1 1 ( 0 ∣ ϵ ) ∗ 1 ∣ ( 0 ∣ ϵ ) |(0 |ϵ) ∣ ( 0 ∣ ϵ )
=
1 0 ∗ 1 ∣ ( 0 ∣ ϵ ) 10^*1|(0 |ϵ) 1 0 ∗ 1 ∣ ( 0 ∣ ϵ ) step(1)
R 01 1 R^{1}_{01} R 0 1 1
=
R 01 0 R^{0}_{01} R 0 1 0 ( R 11 0 ) ∗ (R^{0}_{11})^* ( R 1 1 0 ) ∗ R 11 0 R^{0}_{11} R 1 1 0 ∣ R 01 0 |R^{0}_{01} ∣ R 0 1 0 = 0 ∗ 1 ( 1 0 ∗ 1 ∣ ( 0 ∣ ϵ ) ) ∗ 1 0 ∗ ∣ 0 ∗ = ( 0 ∗ 1 0 ∗ 1 0 ∗ ) ∗ ∣ 0 ∗ = ( 1 0 ∗ 1 ∣ 0 ) ∗ = 0^
∗1(10^∗1 | (0 |ϵ))^∗10^∗
| 0^
∗
= (0^
∗10^∗10^∗
)
∗
| 0^
∗ = (10^∗1 | 0)^
∗ = 0 ∗ 1 ( 1 0 ∗ 1 ∣ ( 0 ∣ ϵ ) ) ∗ 1 0 ∗ ∣ 0 ∗ = ( 0 ∗ 1 0 ∗ 1 0 ∗ ) ∗ ∣ 0 ∗ = ( 1 0 ∗ 1 ∣ 0 ) ∗ Do we need to compute the rest? (i.e
R 01 1 , R 10 1 , R 11 1 R^{1}_{01},R^{1}_{10},R^{1}_{11} R 0 1 1 , R 1 0 1 , R 1 1 1
)
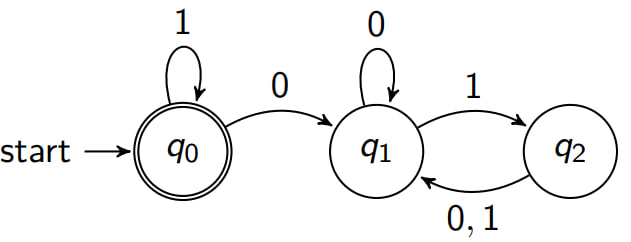
Homework
# Give a regular expression that describes the language accepted
by:
Build a (N)FSA for:
( 11 ) ∗ ( 0 ∣ 1 ) (11)^*(0 | 1) ( 1 1 ) ∗ ( 0 ∣ 1 )